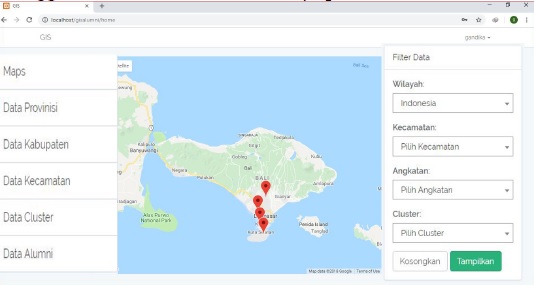
Sistem Informasi Geografis Pemetaan Persebaran Alumni dengan Analisa Clustering
Abstract
STMIK STIKOM Indonesia (STIKI Indonesia) memiliki data alumni yang cukup banyak tetapi data tersebut tidak diolah lebih lanjut untuk menjadi informasi yang lebih berguna. STIKI Indonesia juga kurang mengetahui informasi persebaran alumni di dunia kerja. Untuk mengatasi permasalah tersebut dapat memanfaatkan teknologi Sistem Informasi Geografis (SIG) dan data mining. SIG memiliki kemampuan untuk menyajikan informasi dalam bentuk grafis dan data mining bisa mengekstraksi pola yang tersembunyi dari database besar. Clustering dilakukan pada data alumni dengan atribut bidang pekerjaan, Indeks Prestasi Komulatif (IPK), lama study dan lama pengerjaan tugas akhir. Metode yang digunakan yaitu Fuzzy C-Means (FCM) dan untuk pengukuran validitas cluster menggunakan Modified Partition Coefficient (MPC) dan Classification Entropy (CE). Hasil pengujian menunjukkan bahwa jumlah cluster yang paling optimal adalah 7 cluster dan cluster yang memiliki karakteristik terbaik adalah cluster ke 1 yang jumlah anggotanya 49 (9,3155% dari jumlah keseluruhan alumni), jumlah ini masih sangat kecil jika dibandingkan dengan total keseluruhan jumlah alumni. Pengujian menggunakan metode black box pada Sistem Informasi Geografis Pemetaan Persebaran Alumni dengan Analisa Clustering didapatkan hasil bahwa semua modul dalam sistem telah berfungsi dengan baik.
Downloads
References
[2] M. J. A. Berry & G. S. Linoff, Data mining techniques second edition-for marketing, sales, and customer relationship management, Wiley, 2004.
[3] S. Handoko, “Sistem Informasi Geografis Berbasis Web Untuk pemetaan Alumni Menggunakan Metode K-Means”, tesis, Semarang, Program Pascasarjana, Universitas Diponegoro, 2012.
[4] L. C. Simbolon, N. Kusumastuti, B. Irawan, “Clustering Lulusan mahasiswa Matematika FMIPA Untan Pontianak Menggunakan Algoritma Fuzzy C-Means”, Buletin Ilmiah Mat. Stat. dan Terapannya (Bimaster), Volume 02, No.1 ,2013.
[5] K. Wu, M. Yang, “A Cluster Validity Index for Fuzzy Clustering”, Pattern Recognition Letter, vol.26, pp. 1275-1291, Juli 2005.
[6] F. Hoppner dan F. Klowon , "Learning Fuzzy System - An Objective Function-Approach", Mathware & Soft Computing, vol.11, pp. 143-162, 2004.
[7] K. Hammouda, F. Karaay, A Comparative Study of Data Clustering Techniques. University of Waterloo, Ontario, Canada, 2000.
[8] R. Hadi, I. K. G. D. Putra, I. N. S. Kumara, “Penentuan Kompetensi Mahasiswa dengan Algoritma Genetik dan Metode Fuzzy C-Means”, Majalah Ilmiah Teknologi Elektro, vol. 15, n. 2, p. 101-106, Desember 2016.
[9] A. A. G. B. Ariana, I. K. G. D. Putra, Linawati,” Perbandingan Metode SOM/Kohonen dengan ART 2 pada Data Mining Perusahaan Retail”, Majalah Ilmiah Teknologi Elektro, vol. 16, n. 2, p. 55-59, Agustus 2017.
[10] A.I. Shihab, “Fuzzy Clustering Algorithm and Their Application to Medical Image Analysis”. Dissertation, University of London, London, 2000.
[11] I. M. B. Adnyana,I. K. D. Putra,I. P. A. Bayupati, “Segmentasi Citra Berbasis Clustering Menggunakan Algoritma Fuzzy C-Means”, Majalah Ilmiah Teknologi Elektro, vol. 14, n. 1, Juni 2015.
[12] P. N. Tan, M. Steinbach, & V. Kumar, Introduction to Data Mining. Pearson Education, Inc, 2016.
[13] A. K. Jain, M. N. Murthy & P. J. Flynn, “Data Clustering: A Review”, ACM Computing Surveys, vol. 31, No. 3, 1999.
[14] E. Prahasta, Sistem Informasi Geografis: Aplikasi Pemrograman MapInfo, CV. Informatika: Bandung, 2005.

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.

This work is licensed under a Creative Commons Attribution 4.0 International License